Difference between revisions of "An initial path towards statistical analysis"
| Line 29: | Line 29: | ||
== At least one categorical variable == | == At least one categorical variable == | ||
| + | Your dataset does not only contain continuous data. Is it only categorical, thoughß | ||
<imagemap>Image:Statistics Flowchart - Data Formats.png|650px|center| | <imagemap>Image:Statistics Flowchart - Data Formats.png|650px|center| | ||
poly 328 376 12 696 332 1008 640 688 [[An_initial_path_towards_statistical_analysis#Only_categorical_data:_Chi_Square_Test|Only categorical data]] | poly 328 376 12 696 332 1008 640 688 [[An_initial_path_towards_statistical_analysis#Only_categorical_data:_Chi_Square_Test|Only categorical data]] | ||
Revision as of 09:53, 23 March 2021
This interactive page allows you to find the best statistical method to analyze your given dataset.
Go through the images step by step, click on the answers that apply to your data, and let the page guide you.
Start here with your data! This is your first question.
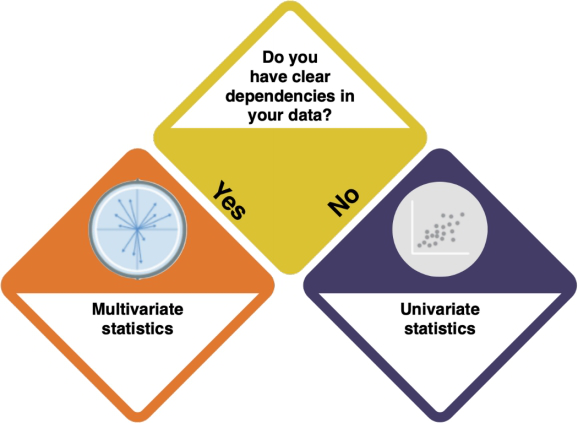

How do I know?
- Inspect your data with
strorsummary. Are there several variables? - What does the data show? Does the underlying logic of the data suggest dependencies between the variables?
Example: Inspecting the swiss dataset
Contents
Univariate statistics
So either have only one variable, or the variables are dependent on each other. But what kind of variables do you have?
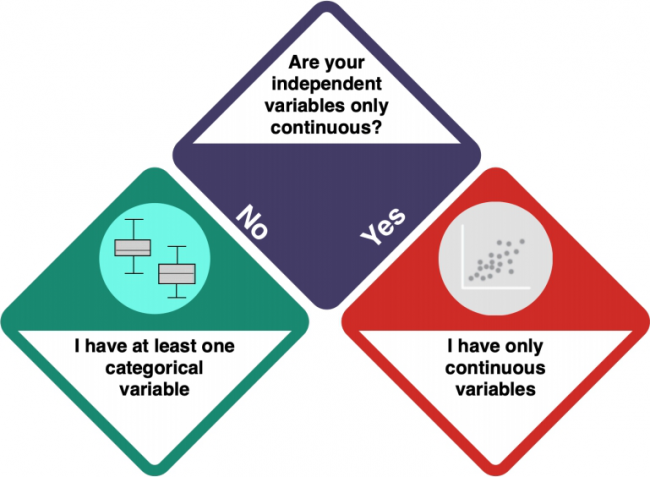

How do I know?
- Check the entry on Data formats to understand the difference between categorical and numeric variables.
- Investigate your data using
strorsummary. integer and numeric data is not categorical, while factorial and character data is.
At least one categorical variable
Your dataset does not only contain continuous data. Is it only categorical, thoughß
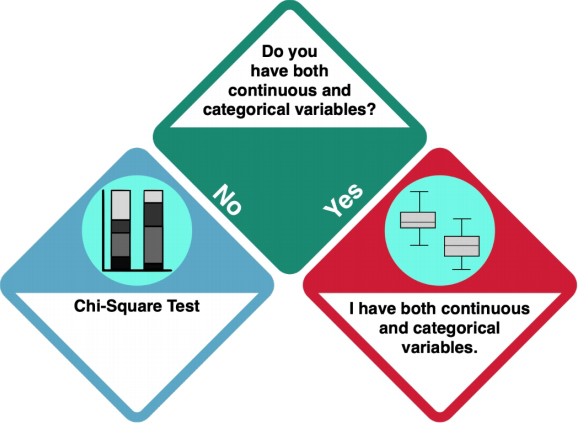

How do I know?
- Investigate your data using
strorsummary. integer and numeric data is not categorical, while factorial and character data is.
Only categorical data: Chi Square Test
If you have only categorical variables, you should do a Chi Square Test. LINK TO CHI SQUARE TEST R EXAMPLE
Categorical and continuous data

How do I know?
- R commands: quantile(), str, summary
- Investigate your categorical dependent variables using...
- ADD MORE
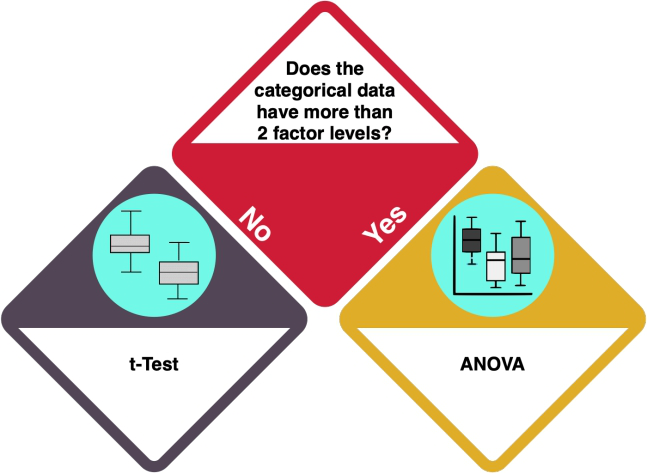
One or two factor levels: t-test
With one or two factor levels, you should do a t-test. A t-test ... ADD. Check the entry on the T-Test to learn more.
Depending on the variances in your data, the type of t-test differs.
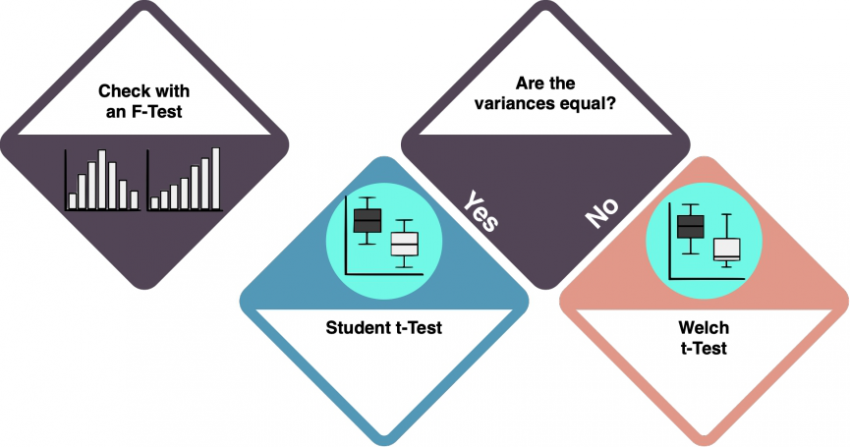

ADAPT THE T-TEST ENTRY SO THAT DIFFERENCE BETWEEN STUDENT AND WELCH IS CLEAR
How do I know?
- Use an F-Test to check whether the variances of the datasets are equal. LINK LEFT BOX TO F-TEST
More than two factor levels
MISSING - COMPLICATED FIGURE
Analysis of Variance
R commands: aov, Anova, ezAnova, var.test(), lm
Relevant figures: boxplot()
Is your dependent variable normally distributed?
R commands: ks.test, shapiro.test, hist
Yes, my dependent variable is normally distributed!
No, my dependent variable is binomial distributed!
No, my dependent variable is Poisson distributed!
Gaussian Anova
R commands: aov, lm
Relevant figures: boxplot
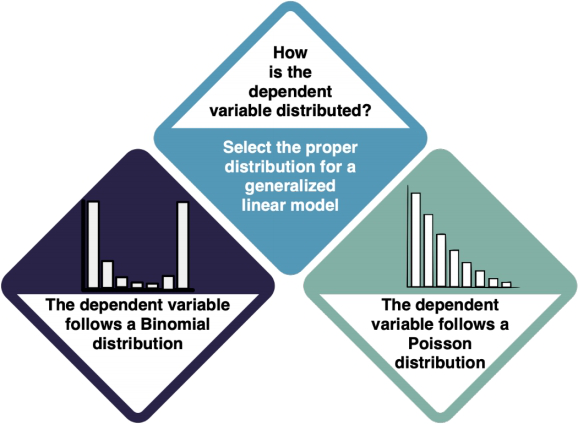
Is your dependent variable binomial or Poisson
Poisson GLM|Dependent variable is count data
R commands: glm,
Relevant figures: plot
Binomial GLM|Dependent variable is 0/1 or proportion
R commands:
Relevant figures:
Type III Anova
R commands: Anova(car)
Relevant figures: boxplot
Data_distribution#Non-normal_distributions|Dependent variable not normally distributed]
Poisson GLM|Dependent variable is count data
R commands: glm
Relevant figures: plot
Binomial GLM|Dependent variable is 0/1 or proportions]
R commands: glm
Relevant figures:
Only continuous variables
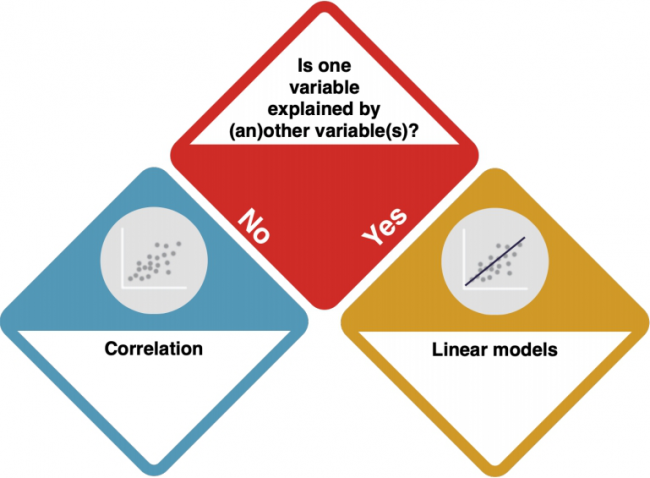

How do I know?
- ADD INFO - HOW DO I KNOW IF THEY ARE DEPENDENT?
No dependencies: Correlations
If there are no dependencies between your variables, you should do a Correlation. A correlation ... ADD. Check the entry on Correlations to learn more. The type of correlation depends on your data distribution.
- ADD INFO ON PEARSON AND SPEARMAN CORRELATIONS; WITH R CODE
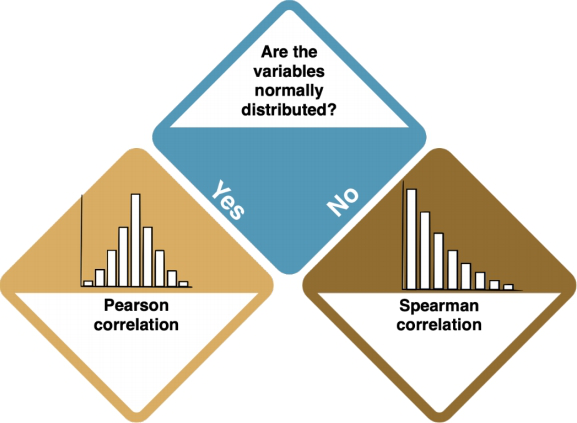

LINK TO CORRELATION R EXAMPLES (pearson, spearman)? How do I know?
- ADD INFO - HOW DO I KNOW IF THE DATA IS NORMALLY DISTRIBUTED?
- Check the entry on Normal distributions to learn more.
Clear dependencies
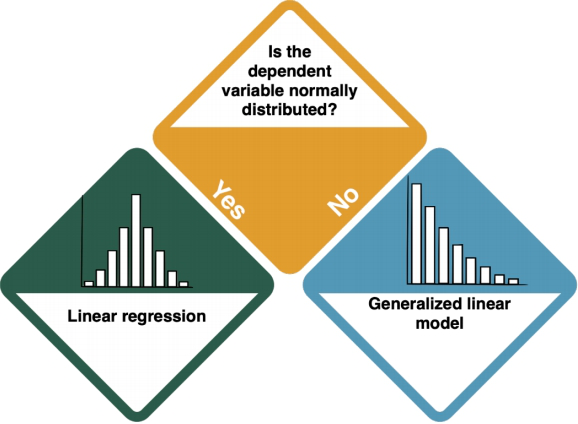

How do I know?
- ADD INFO - HOW DO I KNOW IF THE DATA IS NORMALLY DISTRIBUTED?
- Check the entry on Normal distributions to learn more.
Normally distributed dependent variable: Linear Regression
Not normally distributed dependent variable

How do I know?
- ADD INFO - HOW DO I KNOW THE DISTRIBUTION TYPE?
- Check the entry on Non-normal distributions to learn more.
- For both types of distribution, your next step is the Generalised Linear Model. However, it is important that you select the proper distribution type in the GLM ADD MORE INFO
Generalised Linear Models
With non-normally distributed data, you arrive at a Generalised Linear Model (GLM). GLMs are... ADD
Depending on the existence of random variables, there is a distinction between Mixed Effect Models and Generalised Linear Models, which are based on regressions.
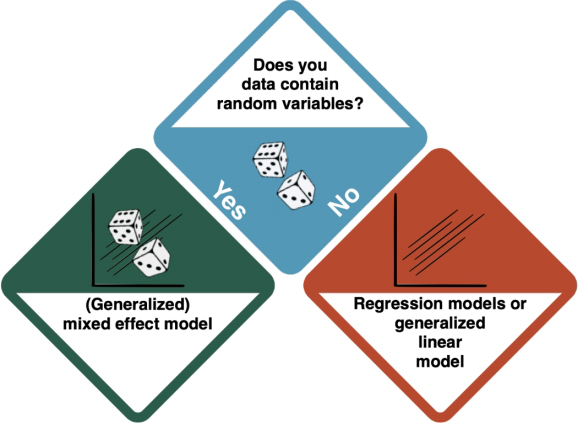

How do I know?
- HOW DO I KNOW IF I HAVE RANDOM VARIABLES???
- R commands: glmer, glmmPQL
Relevant figures:
WHAT IS THIS ABOUT?
Dependent variable is count data
[Binomial GLM|Dependent variable is 0/1 or proportions]]
Multivariate statistics
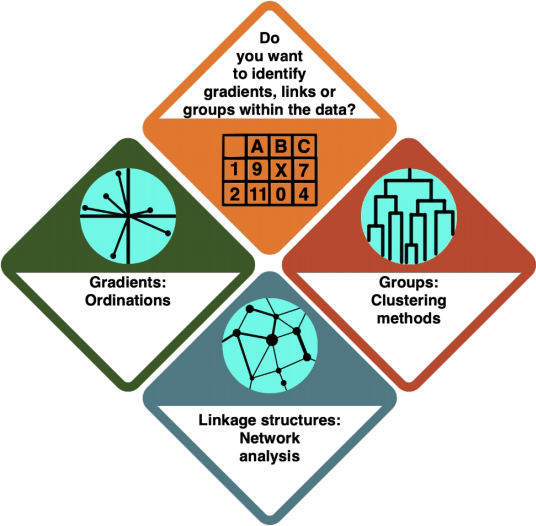

How do I know?
- In an Ordination, you arrange your data alongside underlying gradients in the variables to see which variables most strongly define the data points.
- In a Cluster Analysis, you group your data points according to how similar they are, resulting in a tree structure.
- In a Network Analysis, you arrange your data in a network structure to understand their connections and the distance between individual data points.
Ordinations
You are doing an ordination. An ordination ... ADD Check the entry on Ordinations (to be added) to learn more.
There is a difference between ordinations for different data types - for abundance data, you use Euclidean distances, and for continuous data, you use Jaccard distances.
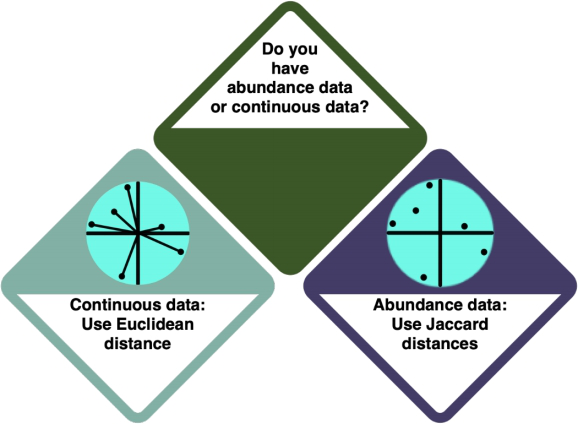

How do I know?
- Check the entry on Data formats to learn more about the different data formats.
- Investigate your data using
strorsummary. Abundance data is marked as FORMATNAME, and continuous data is marked as FORMATNAME.
MAKE THE STUFF BELOW CLEARER - OR LINK SOMEWHERE ELSE?
Linear-based ordinations
Linear-based ordinations are... It uses Euclidean distances, which is...
R commands:
Relevant figures:
Correspondance analysis
A correspondence analysis is... It uses Jaccard distances, which is...
R commands:
Relevant figures:
Cluster Analysis
So you decided for a Cluster Analysis. A Cluster Analysis .. ADD Check the entry on Clustering Methods to learn more.
There is a difference to be made here, dependent on whether you want to classify the data based on prior knowledge (supervised) or not (unsupervised). DIFFERENCE BETWEEN SUPERVISED AND UNSUPERVISED?? DISTINCTION NOT MADE IN THE CLUSTERING ENTRY
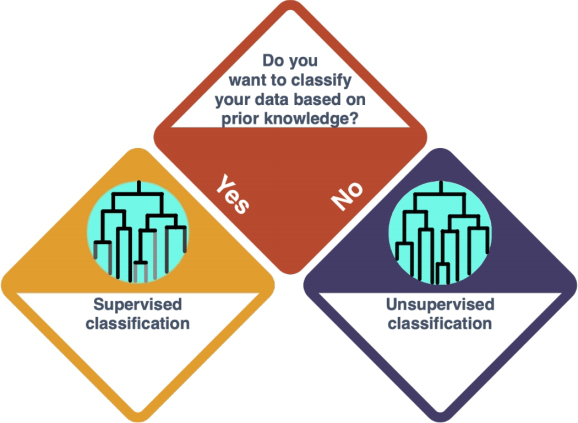

WHERE DO WE LINK?
How do I know?
- HOW DO I KNOW IF ITS SUPERVISED OR NOT?
Network Analysis
You have decided to do a Network Analysis. In a Network Analysis... ADD Check the entry on Social Network Analysis to learn more.
There is a distinction here between bipartite and tripartite networks, with two or three kinds of nodes, respectively.
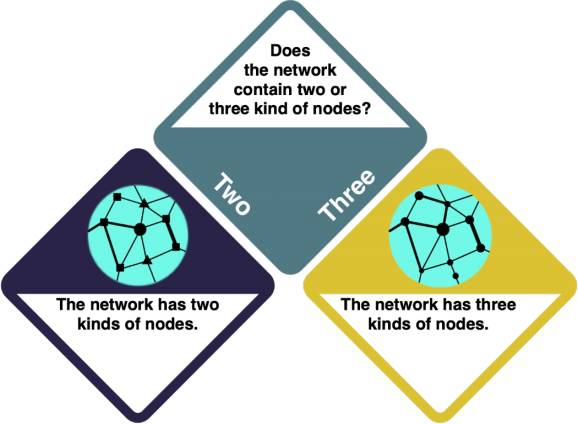

How do I know?
- Check your data using the R code ADD CODE
ADD MORE BELOW - OR DO WE LINK SOMEWHERE ELSE? Bipartite If your data has two different kinds of nodes, your network is called a "bipartite" network.
R commands:
- is_bipartite(graph)
- make_bipartite_graph(types, edges, directed = FALSE)
Tripartite
R commands:
Relevant figures:
Resterampe
Analysis of Variance
INSERT TYPE II
INSERT RANDOM FACTOR
INSERT LMM
Dependent variable is count data
Dependent variable is 0/1 or proportions