Data Versioning with Python
Contents
Motivation
As data projects evolve more data is collected, annotated and modified, and models are built, optimized, and re-built on new datasets. If we manage several versions of a code with different modifications and complementary explanatory comments, we call that versioning. It is especially important to guarantee the reproducibility of an experiment.
Most data scientists work with GitHub for versioning code, but it is not ideal to version datasets, models, and metrics as Github has a strict file limit & it cannot handle large files & directories. It can also get very tricky for comparing different versions of data.
DVC (Data Version Control) is built to make different data projects shareable and reproducible. It is an ideal tool for versioning binary data and is especially designed to handle large files, data sets, machine learning models, and metrics. However, we cannot view the DVC tracked files on GitHub.
DAGsHub platform enables data scientists and machine learning engineers to version their data, models, experiments, and code.
Entering the Era of Machine Learning Operations & Machine Learning Lifecycle Processes
Machine Learning Operations (MLOps) is a term used to describe the set of processes and tools that help manage the end-to-end lifecycle of machine learning models. This includes everything from data preparation, feature engineering, model training, model deployment as well as model monitoring.

Sketch of an ML Project Lifecycle. Figure source
Introduction to Data Version Control
DVC is to Machine Learning Engineers what Git is to Software Engineers
The author of this entry is XX. Edited by Milan Maushart
DVC is the main tool for MLOps and enables data versioning through codification and captures the versions of the data and models in Git commits. It also provides a mechanism to switch between different data contents.
Importance of Data Versioning,
- Ensure better training data
- Track data schema
- Continuous model training
Installing DVC
Follow [[1]] guide to install DVC on alternative machines.
pip install dvc
Adding Datasets into Git Repo
dvc add path/to/dataset
NOTE: Regardless of the size of the dataset, the data will be added to the repository.
Basic Uses of DVC:
- Similar to code versioning, track and save data and machine learning models
- Easily switch between versions of data and ML models
- Understand how datasets and ML artifacts were built initially

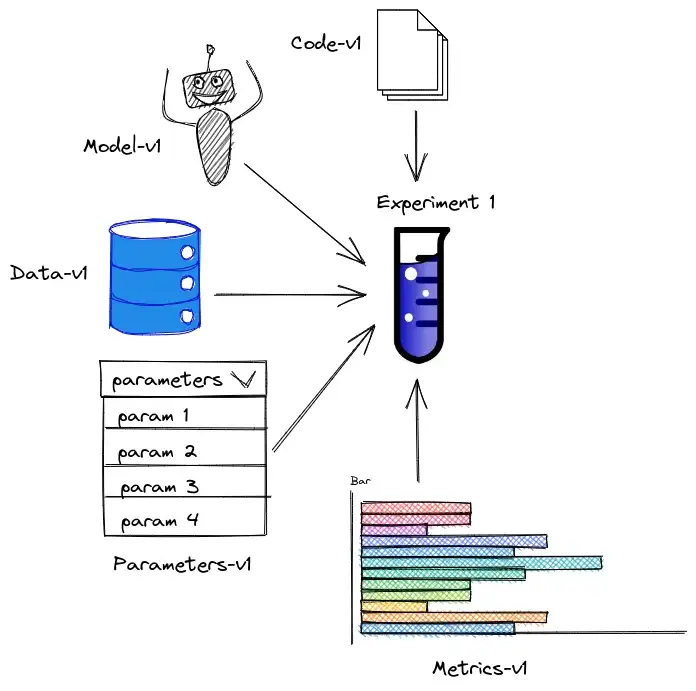
DVC matches the right versions of data, code, and models, source
Introduction to DAGsHub
DAGsHub is to Machine Learning Engineers what GitHub is to Software Engineers
DAGsHub is a web platform that leverages popular open-source tools to version datasets models, track experiments, label data, and visualize results. It is a free-to-use web platform similar to GitHub for an open-source data science project. DAGsHub supports inbuilt tools like Git for source code tracking, DVC for data version tracking, and MLflow for experiment tracking, which allows us to connect everything in one place with zero configuration.

DAGsHub all-in-one Platform, source
{kind=link}
We can further integrate tools like MLflow, DVC, Jenkins, etc. into the platform to perform experiments and gather insights on processes.
Follow this tutorial to start with the basic project on DAGsHub using DVC
The author of this entry is XX. Edited by Milan Maushart